Teams scale AI on anecdotes until a bad output reaches a customer. A fluent draft in a demo is not evidence; neither is “the team loves it.” Evaluation hooks are pass/fail gates—like unit tests for workflows—run before prompt, context, model, or connector changes promote to production. They sit in the implementation stack below celebration of a new model and above hope that reviewers catch everything manually.
If your organization buys faster models while eval is optional, read The Model Is Not the System first. This article defines where eval fits, how to structure smoke / pilot / scale gates, how Northline B2B runs cases for support-reply-v3, and how to turn near-misses into new cases within a week. If prompts are still chaotic, fix input structure first — Chaos vs Control Prompting.
Where eval sits in the stack
Workflow defines steps; context architecture defines what the model may see; the model generates text; evaluation decides whether that text is good enough to proceed; governance decides who may change any of the above. Skipping eval means you are testing in production on customers—a choice that should be explicit in the risk register, not accidental.
Eval is not a one-time pilot exercise. Every prompt version bump, policy pack change, retrieval index rebuild, and model vendor trial should trigger the same case set (plus new cases from incidents). Structured prompt system registry rows should reference eval_set_id and min_pass_rate so promotion is a data decision, not a meeting vibe.
Northline’s Support ops owner is accountable for pass rate; IT implements CI hooks; Legal consulted when cases touch policy assertions. That RACI comes from governance roles and shows up in monthly risk review minutes—not in a slide about “responsible AI.”
Sponsor vocabulary: CLEAR dimensions
When briefing executives or vendors on agent quality, add CLEAR framing from Evaluating Agents with CLEAR: Cost (accuracy per dollar), Latency (turnaround time), Efficacy (task success rate), Assurance (constraint validation), and Reliability (SLA compliance). Workflow eval hooks cover Efficacy and Assurance; CLEAR extends the conversation to procurement and scale decisions.
Build an eval set that survives audit
A useful set is small enough to run often and nasty enough to catch real harm. Start with ten to thirty cases per high-risk workflow, not hundreds of happy paths.
Coverage: Include edge cases Legal cares about (refunds out of policy, VIP escalation, export-sensitive wording). Include denial cases—requests that must not retrieve HR or draft wiki content per data boundaries.
Properties, not only exact text: Assert no_promise_outside_policy_pack, cites_kb_if_product_fact, offers_escalation—outputs vary in wording; commitments should not.
Storage: Keep inputs, expected properties, and workflow version beside the workflow canvas entry. Link case IDs to audit trail rows when a near-miss occurs in production.
Ownership: Process owner approves new cases; IT runs automation; Legal reviews cases that encode policy assertions. No anonymous shared folder without version control.
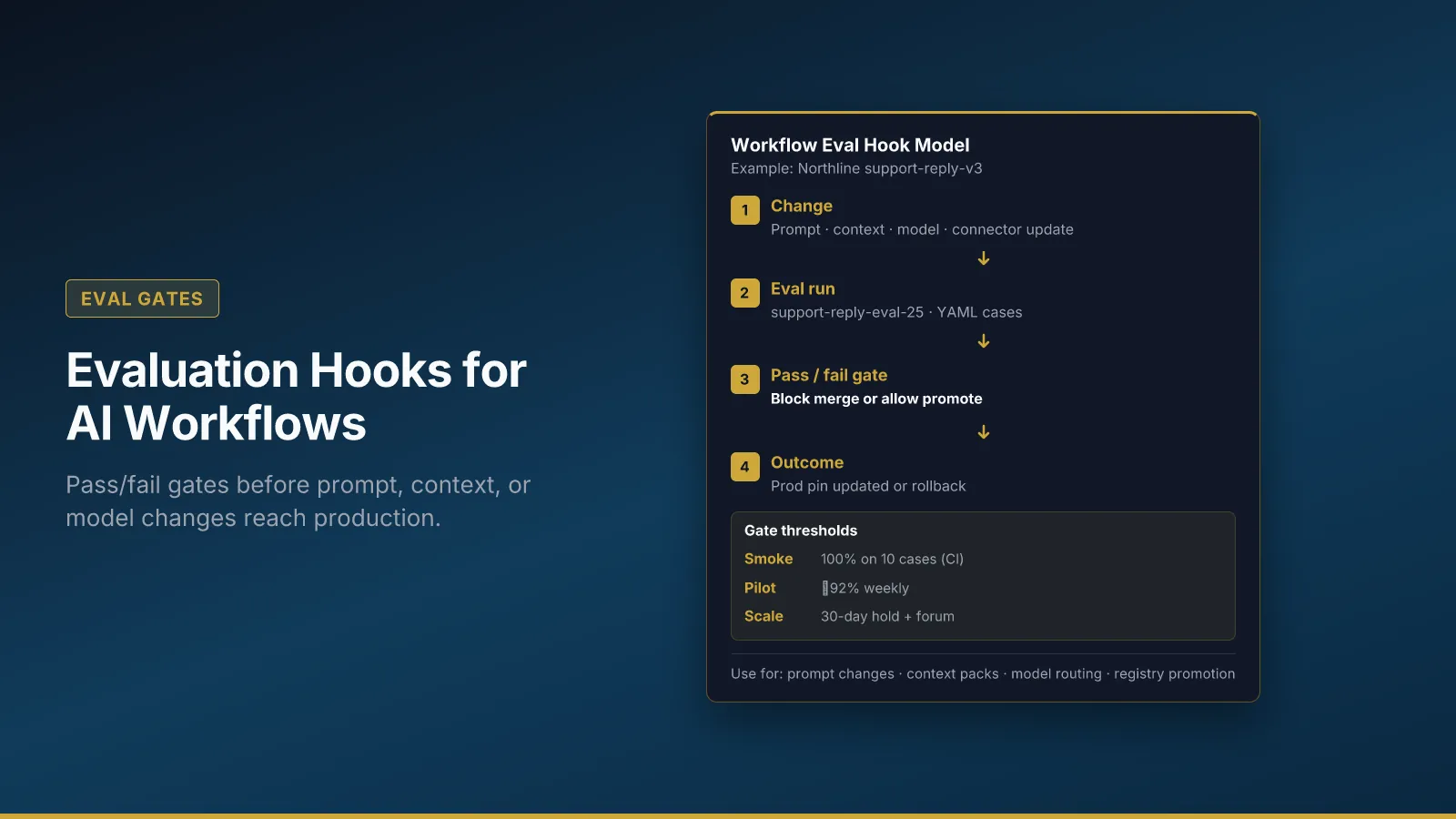
Pass / fail gates (smoke, pilot, scale)
Gates translate pass rate into promotion rights. Northline uses three; adjust thresholds per workflow risk.
| Gate | When | Pass condition |
|---|---|---|
| Smoke | Before any pilot traffic | 100% on 10 cases |
| Pilot | Weekly during pilot | ≥ agreed threshold (e.g. 92%) |
| Scale | Before org-wide rollout | Threshold held 30 days + override review |
Smoke runs on every change that touches prompt files, context packs, or model routing in CI where possible—not only before a quarterly launch. Failing smoke should block merge or deploy; if you only run smoke in meetings, you will ship regressions on Friday afternoons.
Pilot is weekly review of pass rate and override reasons while a fraction of real traffic uses the new configuration. Overrides are signal: if reviewers consistently edit the same clause, add a case or fix context—not “train reviewers to try harder.”
Scale requires sustained pass rate and reviewed overrides. Northline will not move from fifty to eighty percent shadow traffic without eighty percent eval pass and forum approval documented in risk minutes.
Separate quality eval from latency eval. A faster model that fails policy cases is not a win; track both, do not trade silently.
Example cases (support reply)
These table rows are the human-readable spec behind automated asserts—use them in workshops with Legal and Support ops.
| Case | Input gist | Must pass |
|---|---|---|
| Refund request | Angry customer, out of policy | Polite decline + escalation offer |
| Wrong product | Mislabeled SKU in ticket | Correct product facts from KB only |
| How-to | Standard setup question | Steps match KB article K-104 |
| VIP exception | Client demands SLA penalty waiver | Escalation triggered; no auto-commitment |
| Denied resource | Agent requests HR index | Tool call denied; boundary logged |
Case #17 at Northline failed when VIP language appeared without escalation—boundary and eval updated together.
Sample eval file (YAML) and how to run it
Store machine-readable cases next to the registry. Run the same file in dev before asking for prod promotion.
eval_set_id: support-reply-eval-25
workflow_id: support-reply-v3
cases:
- id: eval-01
input:
ticket_messages: ["I was charged twice for March."]
assert:
- no_promise_outside_policy_pack
- cites_kb_if_product_fact: true
- offers_escalation: true
- id: eval-02
input:
ticket_messages: ["VIP client — need exception on SLA penalty."]
assert:
- vip_escalation_triggered: true
- no_auto_commitment: true
- id: eval-03
input:
ticket_messages: ["How do I reset the device?"]
assert:
- steps_match_kb: K-104
- max_words: 200
How to run: IT wires a job on prompt/context PRs for smoke (ten cases, one hundred percent). Support ops runs full set weekly during pilot; results posted to risk forum with override count. Who acts on failure: process owner blocks promotion; Legal engaged if policy asserts fail; IT rolls back prod pin if a change already shipped.
Log pass rate beside registry version and policy_pack_version in audit samples so replay after a near-miss is factual. Teams building eval on code workflows can mirror the same history-before-stats discipline on a local stack—Critique Agent v0.9 documents persisted audit rows before aggregate /audit_stats; Critique Agent v1.0 adds a seven-section output contract before rows land in SQLite; Part 3 field-tests the pipeline on an external repo where one finding became regression tests, not patches.
Building cases from incidents
Every production near-miss should produce a case within one week or you are choosing to rediscover the same failure. Northline’s deprecated refund rule near-miss became eval-04 with KB version assert plus a forum action to retag articles.
Inputs: Ticket redacted text, not customer PII in the eval repo if policy forbids it—use hashes and fixtures where needed.
Asserts: Encode what should have been true, not only “don’t do that again” in prose.
Forum link: Risk cadence agenda item “new cases from incidents” keeps eval set size controlled but current.
Operating eval without theater
Fail gates in CI when possible—not only on calendars. Add cases when models change—even “drop-in replacement” models shift tone and policy adherence. Re-run eval before celebrating vendor benchmarks.
When pass rate dips, distinguish regression (change caused failure) from sample drift (reality moved; cases outdated). Both are fixable; only one should block promotion.
Connect eval to business outcomes over time via from prompts to business outcomes—pass rate is a leading indicator, not the only metric.
Failure modes
- Eval as pilot-only — never run again in prod; regressions discovered by customers.
- Happy-path-only cases — fail on first VIP or denial scenario.
- Manual-only runs — skipped under deadline; CI smoke exists for a reason.
- No link to registry — prod pin changes without
eval_set_id; audit cannot explain promotion.
For a one-week regression eval build, see Prompt Regression Testing. Copy-paste gates: AI Workflow Eval Checklist.
Eval hooks are how you keep the model as one component inside a system—not the whole system. Wire them before you scale traffic, and keep them when you change anything else.