Part 1 — measurement: history before stats.
| Part | Article | Lesson |
|---|---|---|
| 1 | When Local Audit Stats Earn Trust (this post) | History before stats |
| 2 | Critique Agent v1.0: Verified Local Code Audits | Validate before persist |
| 3 | Critique Agent: Field Test | Trust workflow, not verdict |
After a near-miss, Legal does not want a chat transcript—they want a row they can replay: verdict, file reference, confidence, retry flag, timestamp. Pasting a code block into a cloud chatbot is fast and operationally hollow. The model guesses from zero project context, returns prose you cannot gate, and leaves nothing durable behind.
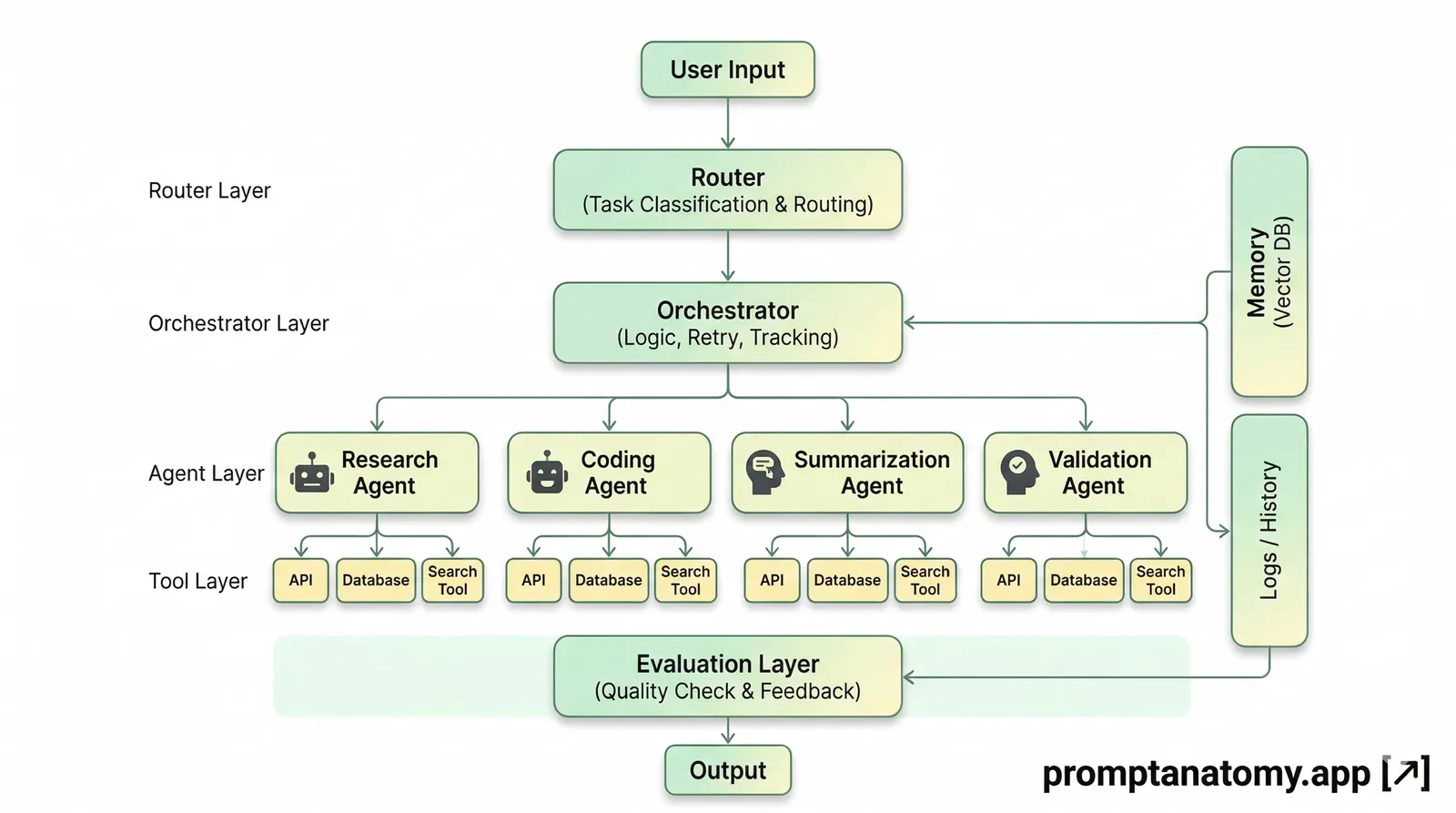
I built Critique Agent on a local Ubuntu stack (Ollama, Gemma 12B, Pydantic AI) to close a smaller loop first: structured local audit, persisted history, aggregate stats—not a ChatGPT clone. The hero diagram frames the destination: before, a chatbot judges from zero context; now, an agent reads the repo before judging it. v0.9 does not ship full repo context or file inspect yet. It ships /audit_stats on top of the v0.8 audit loop. For the wider lesson that inference is not the system, see The Model Is Not the System.
Northline’s platform lead ran weekly /audit_stats for a month—the GO mix looked healthy. Then security asked for replay on a flagged merge. The rows existed, but nothing in them documented what “validated output” meant run to run. Aggregates without a stable contract lie with the same confidence as good ones. That gap is what v0.9 closes at the measurement layer—and what Critique Agent v1.0 closes at validation.
What v0.8 already closed
Before aggregate stats, I needed a minimum useful audit loop that could run in a real CLI session and survive pytest. v0.8 delivered that end to end:
select code block → local audit → validate structured output → retry once if invalid
→ persist accepted result → retrieve recent audit history through CLI
Each accepted run stores a structured verdict—not free text. The enum is GO, GO_WITH_NOTES, or FIX, with confidence, file reference, retry flag, and a timezone-aware UTC timestamp. Invalid structured output triggers one retry; if validation still fails, the run does not land in history as a false positive. Prompting was improvisation; GO / FIX enums with one retry is the first time elif felt like governance.
A real persisted row from development looked like this:
#1 | GO_WITH_NOTES | confidence: High | chat_agent.py:339-397 | retry: false | 2026-06-11T14:02:13.776796
That format is deliberate. Evaluation Hooks for AI Workflows treat pass/fail gates as promotion rights; this CLI encodes the same discipline for a single-agent code critique—schema first, retry once, persist only accepted rows. Audit Trails for AI Workflows ask what you can reconstruct after an incident; here the minimum is verdict, location, confidence, retry, and timestamp—not a chat transcript.
The /audit_history command lists recent rows newest first. Everything runs 100% local—no API keys, no egress. Stack and install details live in the sister repo, not duplicated here.
What v0.9 adds — /audit_stats
I added /audit_stats only after /audit_history stayed stable in real CLI runs and tests. Aggregates without reliable history lie about quality—you would be charting a schema still in motion.
The command answers an operator question history alone cannot: is the agent getting stricter or sloppier over time? Example output shape:
Total audits: 12
GO: 5
GO_WITH_NOTES: 4
FIX: 3
Retries used: 2
First time those numbers came from real runs—not demo data—I cared more about FIX: 3 than any fluent paragraph Gemma ever gave me.
Use it in weekly review the same way teams use CLEAR scorecards—Evaluating Agents with CLEAR separates efficacy from assurance and reliability. /audit_history is the drill-down row; /audit_stats is the weekly headline. If FIX counts climb after a model swap, you have a signal to freeze promotion until eval cases catch up—not a vibe in standup.
v0.9 intentionally does not add file filtering, pagination, embeddings, RAG, multi-agent orchestration, or dashboards. Stats are the smallest next command that still teaches something about operating a local agent.
Hero boxes — shipped vs roadmap
The repo-brain hero lists five capabilities. Treat it as a roadmap with honest status, not a feature checklist.
| Hero box | Status in v0.9 |
|---|---|
| Memory | Shipped — memory_store, /audit_history |
| Audit | Shipped — structured verdicts; v0.9 adds /audit_stats |
| Smart Prompting | Shipped — Pydantic AI schema + single retry on invalid output |
| Context | Roadmap — repo-aware context before verdict |
| Inspect | Roadmap — targeted file read before audit |
Next build steps follow How to Design an AI Agent Workflow: add context and inspect as bounded tools with the same structured output and persist rules—still no RAG, still no embedding index, still no multi-agent handoffs until the single-agent audit loop is boring.
Operating discipline (what I would not skip again)
Two decisions kept v0.9 shippable:
- History before stats.
/audit_statscame after/audit_historyworked in CLI and pytest—not the reverse. - Schema before fluency. A chatty local model that ignores
GO/FIXenums is a demo, not an agent.
Embeddings, RAG, orchestration, and dashboards stay on the do not do yet list until history and stats prove stable.
Same energy as the rush—aimed at rows you can diff. Less theater, more GO / FIX. Still fun. If you are building your own local critique agent, copy the loop, not the poster: enforce structured output, persist accepted audits, list history, then aggregate. Next in the series: Critique Agent v1.0—what accepted means before SQLite persist; then Part 3—cross-repo field test, false positives, and one regression-test payoff. Context and repo inspect belong on the hero because they are the next chapter—not because v0.9 already shipped them.