Part 3 — field test: trust the workflow, not the verdict.
The agent was useful because I did not trust it blindly.
Parts 1 and 2 proved measurement and validation on the Critique Agent home repo. Part 3 field-tests the same pipeline on Corporate Ladder—the Telegram mini app monorepo at DITreneris/ladder—while a human still judges every verdict. When Local Audit Stats Earn Trust closed history-before-stats; Critique Agent v1.0 closed validate-before-persist. Six structured audits, several false positives, one regression-test payoff. See soft launch and v2.4 score-trust for the game context. For the wider frame that inference is not the system, see The Model Is Not the System. Sister-repo operator lab builds are indexed in The Prompt Anatomy Ecosystem Map.
Why build a local code critique agent?
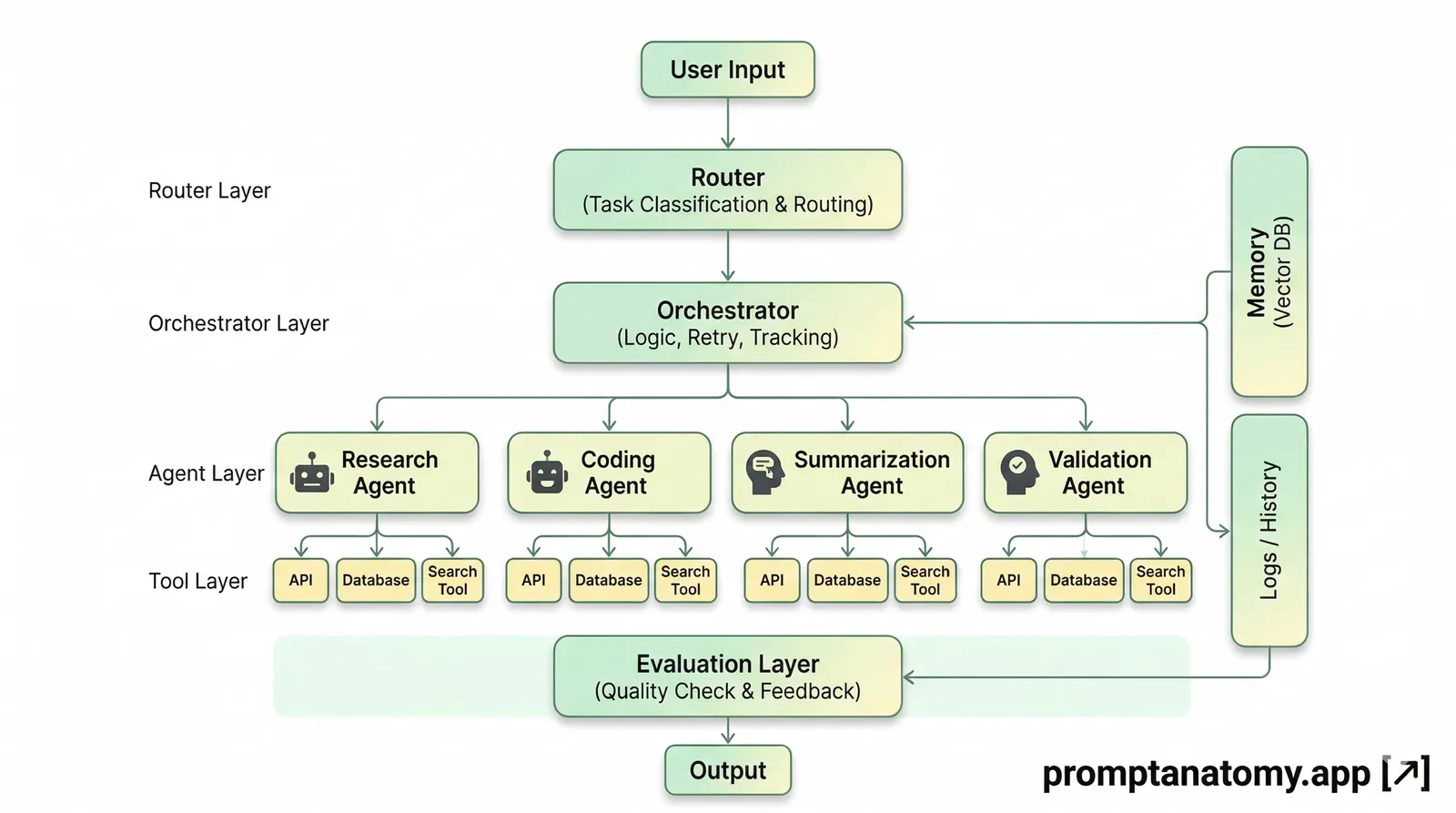
The goal was never a magic fixer. I wanted a CLI-first, local-first assistant that could review a chosen code segment during a working session and leave something durable behind. Cloud APIs are fast to demo and weak on accountability unless you wrap them yourself: no stable schema, no persisted history, no gate you can pytest.
A useful local agent should improve decision quality, not remove engineering judgment. That means constrained scope—bounded line ranges, path traversal blocked, structured verdict enums—and output you can reject without polluting history. Stack and install details live in the Critique Agent repo; this post stays on the field-test lesson. If you are designing agents from first principles, How to Design an AI Agent Workflow is the hub that matches how this project grew: constraints before intelligence, tools before autonomy.
What had to work before a field test?
Parts 1 and 2 already shipped the minimum loop I would not skip again. The operator selects a code segment; the local model returns critique; a seven-section validator checks structure; invalid output gets one repair retry; if validation still fails, the run is rejected and not stored. Accepted runs land in SQLite with verdict, confidence, file reference, line range, retry flag, and UTC timestamp—what Audit Trails for AI Workflows need for replay (see Part 2 for the full contract).
Select Code → Local Audit → Validate Output → Save Result → Review History
Invalid ↓ Retry Once (repair) ↓ Still invalid → Reject (not stored)
I did not run the Corporate Ladder field test until /audit_history and the seven-section contract were boring in pytest. Aggregates and field tests both lie if “accepted” is still moving. Part 3 assumes that gate is closed—if you are still improvising prompt shape, fix validation first.
How do you field-test Critique Agent on Other Project?
Real confidence requires running the agent from a sister repo you are actively shipping—not only from the Critique Agent home tree. I ran the field test on Corporate Ladder, the Telegram mini app on promptanatomy.lol (soft launch field note, v2.4 score-trust sprint). Same monorepo: DITreneris/ladder (packages/api, Supabase RPC submit paths, pytest suite). I created a Python 3.12 environment (Ubuntu 26.04 shipped 3.14; the pydantic-core stack was not ready yet—one blocker, not a tutorial), ran the test suite green, then launched Critique Agent from that repo root.
The agent resolves project root relative to the working directory—PROJECT_ROOT = Path(".")—so the same CLI becomes a cross-repo reviewer on any sister project you are actively building. /context confirmed the Corporate Ladder root; /project_files indexed the tree; /audit_lines worked on chosen segments; legacy /audit_file correctly stayed secondary for larger files. Focused targets beat full-file noise—the more precise the audit scope, the more useful the signal.
What did six validated audits actually prove?
The pipeline did not crash. Validation did not burn retries. Every run that persisted passed the same contract Part 2 defined.
| Metric | Result |
|---|---|
| External repository | Corporate Ladder — DITreneris/ladder monorepo (promptanatomy.lol) |
| Audits run | 6 |
| Verdict | 6× GO_WITH_NOTES |
| Validation retries | 0 |
| False positives (human triage) | ~4 |
| Code patches from audits | 0 |
| Tests added | 2 regression tests |
| Final test suite | 67 passed |
| Most-audited file | packages/api/app/routes/runs.py |
That table is the honest headline: six structured audits, zero repair retries, zero auto-fixes. It also carries the caveat that matters for operators and for search engines quoting this post: valid does not mean correct. Schema-valid output can still be wrong about the code in front of it.
What false positives showed up?
The agent was useful precisely because I expected noise and triaged manually. Several findings sounded authoritative and failed on inspection:
| Model claim | Reality | Lesson |
|---|---|---|
| Exception may fall through to legacy path | Not supported by visible control flow | Infers branches not shown in the segment |
tg_user missing |
Function parameter in scope | Variable-scope hallucination |
%s logging is wrong |
Standard Python logging pattern | Style vs defect confusion |
Broad except in health check |
May be intentional degraded mode | Context-free best-practice noise |
None of these invalidated the workflow. They reinforced why Evaluation Hooks for AI Workflows treat pass/fail gates as promotion rights—you gate shape first, then apply human judgment to content. A critique agent that only generates better review signals is still valuable if the operator knows not to merge on verdict alone.
When should an AI audit become a test, not a patch?
One audit out of six deserved action. On the atomic run-submit path (_submit_atomic.py)—the same RPC surface Corporate Ladder v2.4 hardened for plausibility filing—the agent flagged that RPC missing detection relied on exception string matching—fragile if error messages shift. The right response was not a risky refactor driven by local-model confidence. I added two regression tests:
- missing
submit_run_atomicRPC →RpcUnavailableError - generic DB/RPC failure → HTTP 503
The suite moved from 65 passed to 67 passed; commit df67b0e landed on main with no behavioral rewrite beyond test coverage. That is the payoff line I would ship to any team asking whether local AI review is worth the setup: out of six structured audits, one became action. Two regression tests, full suite green, no risky refactor.
The same discipline shows up in Prompt Regression Testing Week—freeze cases, tie promotion to pass rate, prefer artifacts you can diff. On a local stack, the artifact is often a test, not a patch.
What would I improve next?
Two upgrades would sharpen signal without expanding scope into a platform:
- Tighter defect vs style separation in audit prompts so logging conventions and intentional broad catches stop masquerading as verified defects.
- Smarter default segment selection—function- and method-aware boundaries already help; defaults should nudge operators toward the smallest segment that still carries behavioral meaning.
Embeddings, RAG, and auto-fix loops stay off the roadmap until field tests like this one stay boring. Bounded tools first—same rule as How to Design an AI Agent Workflow.
Final lesson
I started by trying to build a code critique agent. I ended up learning that the most valuable agent is not the one that writes the patch for you. It is the one that helps you notice where a test should exist—and leaves a row behind when you decide to act.
Copy the pipeline from Parts 1 and 2: validate before persist, list history, then aggregate. Part 3 adds the operator rule: trust the workflow, not the verdict. Build details and commands stay in the Critique Agent repo.