Part 2 — validation: define accepted before persist.
If you chart agent quality from saved runs, accepted must mean the same thing every time—not “the model sounded confident.” When Local Audit Stats Earn Trust made aggregate pass rates visible—/audit_history for drill-down rows, /audit_stats for the weekly headline. That only helps when saved rows mean the same thing run to run.
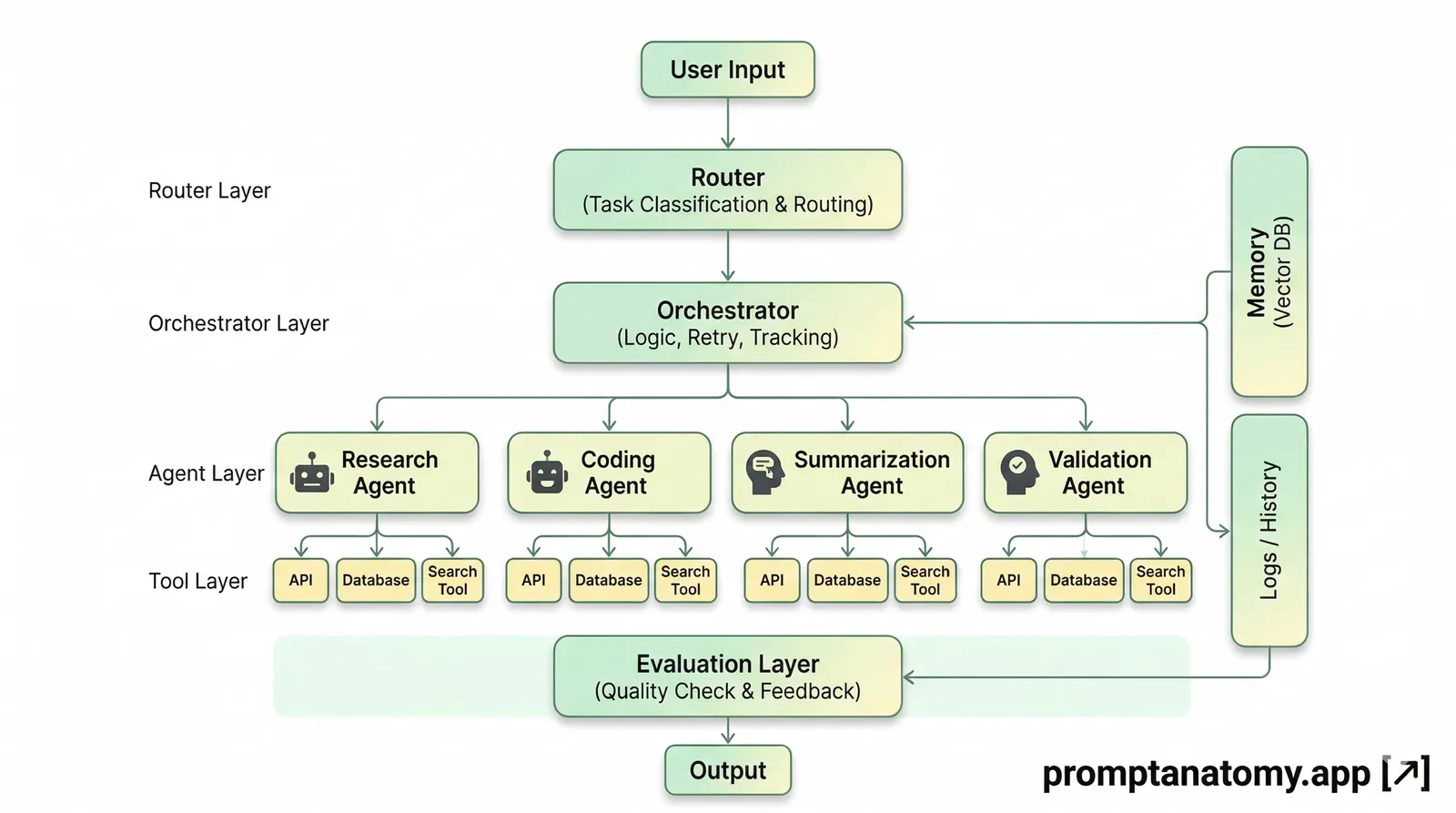
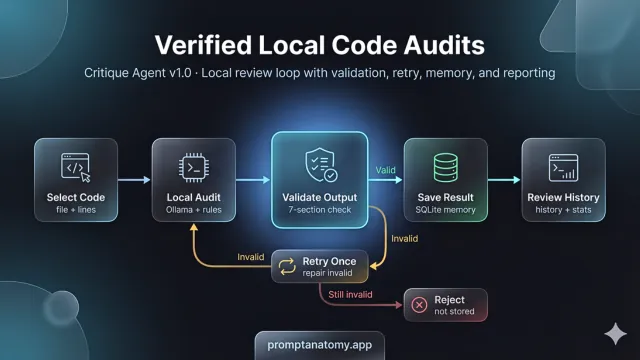
v1.0 is the gate before persist: verified local code audits where output must pass a seven-section contract before SQLite accepts it. The v0.9 hero was a destination poster; this hero is the mechanism—select, audit, validate, save, review. Building block by block made the pipeline obvious once you stop adding features sideways. For the wider lesson that fluent inference is not the system, see The Model Is Not the System.
What v0.9 did not guarantee
v0.8 closed the minimum loop: run local audit, validate structured output, retry once, persist accepted results, list history. v0.9 added aggregates on top. Neither version fully documented what “validated output” meant for a code-segment audit before v0.6–v1.0 work landed. A verdict enum alone can pass while sections are missing, misordered, or padded with generic approval. Gemma could return readable critique that failed the contract—or soft GO prose when practical risks were visible. Stats on bad rows lie with the same confidence as stats on good ones. v1.0 fixes the definition of accepted before /audit_stats earns trust.
The v1.0 pipeline (walk the hero)
The hero diagram reads left to right. Each box is a CLI stage you can replay after a near-miss:
Select Code → Local Audit → Validate Output → Save Result → Review History
Invalid ↓ Retry Once (repair) ↓ Still invalid → Reject (not stored)
Select code — the operator sends only a chosen line range (max 200 lines), with path traversal blocked. Local audit — Ollama runs Gemma with audit rules (low temperature) via a native chat path, not a cloud API. Validate output — a fixed validator checks the seven-section contract; this is the glowing gate on the hero. Save result — accepted runs land in SQLite. Review history — /audit_history and /audit_stats from v0.9 read only persisted rows.
Invalid output triggers one repair retry; if validation still fails, the run is rejected and not stored—no false-positive row for Legal to misread later. Prompting was improvisation; seven sections with one retry is the branch tree you can pytest. That is the same promotion discipline as workflow eval: Evaluation Hooks for AI Workflows treat pass/fail gates as release rights; here the gate is a single-agent CLI audit before SQLite.
Seven-section contract
The validator enforces a fixed markdown contract. Checks include: response starts with 1. Bottom line; all seven numbered headings present, in order, non-empty; forbidden phrases such as Self-Correction rejected; no unexpected content before section 1; response ends after section 7.
| # | Section | Validator intent | Typical failure |
|---|---|---|---|
| 1 | Bottom line | One-paragraph summary tied to the provided code only | Generic praise with no code reference |
| 2 | Verified defects | Concrete, visible runtime/security/workflow defects | Invented missing functions or theoretical bugs |
| 3 | Non-blocking risks | Practical risks that do not block ship today | Stylistic noise reported as defects |
| 4 | Assumptions | Dependencies the audit inferred from visible code | Claims about files not in the segment |
| 5 | Future improvements | Optional hardening—not mixed into verdict | Disguised defects labeled as “nice to have” |
| 6 | Verdict | GO, GO_WITH_NOTES, or FIX (persisted enum) |
Wrong enum or verdict contradicting section 2 |
| 7 | Confidence | High / Medium / Low for the verdict | Missing or empty confidence line |
A real persisted row from development (after validation passed) looked like this:
#1 | GO_WITH_NOTES | confidence: High | chat_agent.py:339-397 | retry: false | 2026-06-11T14:02:13.776796
The long-form seven-section body stays in CLI output; the database row captures what Audit Trails for AI Workflows need for replay—verdict, file reference, line range, confidence, retry flag, and UTC timestamp—not a chat transcript.
v1.0 usefulness hardening
Structure without judgment still wastes operator time. v1.0 tightened audit prompts while keeping the validator enum unchanged (GO | GO_WITH_NOTES | FIX) to avoid compatibility risk:
- Audit only the provided segment—no invented defects or dependencies.
- Require practical failure modes for focused code audits; anti-generic approval guidance.
- Separate verified defects, non-blocking risks, assumptions, and future improvements in prose—not blended into a single vague warning block.
- Stricter prompt-level verdict guidance so soft
GOanswers do not slip past visible edge-case or maintainability risks.
Prompt changes are releases. Treat them like regression cases: Prompt Regression Testing freezes eval sets and ties pass rate to promotion—the same discipline on a local stack when you harden audit prompts after a model swap.
The inference stack is unchanged from v0.9—100% local, no egress. Install and dependency details live in the sister repo.
Shipped vs roadmap
| Item | v1.0 | Still next |
|---|---|---|
| Seven-section validate + retry/reject | Shipped | — |
| SQLite persist on line-range audit | Shipped | — |
/audit_history, /audit_stats |
Shipped (v0.9) | — |
| Audit usefulness / anti-soft-GO prompts | Shipped (v1.0) | — |
| Repo Context / Inspect (repo-brain poster) | Roadmap | Bounded tools first |
/audit_file legacy path |
Unchanged | Align with shared runner later |
| RAG, embeddings, dashboards | Deferred | Same as v0.9 |
Next bounded capabilities follow How to Design an AI Agent Workflow—add context and inspect as tools with the same structured output and persist rules, still no embedding index until the single-agent audit loop is boring.
Operating discipline (what I would not skip again)
Three decisions kept v1.0 shippable:
- Validate before persist. Seven-section contract gates SQLite—not the reverse.
- History before stats.
/audit_statsonly summarizes rows that passed validation (v0.9 discipline still applies). - Defer the platform. Embeddings, RAG, orchestration, and dashboards stay on the do not do yet list.
I stopped adding features when duplication showed up—that was the first time the project felt like a system, not a script stack. Still fun when pytest goes green. Copy the pipeline on the hero, not the repo-brain poster. Enforce the seven-section contract, reject invalid output without storing, list history, then aggregate. Context and repo inspect remain the next chapter on the poster—not because v1.0 already shipped them.
Next in the series: Critique Agent: Field Test—Part 3 field test on an external repo, false positives, and one regression-test payoff.