Part 1 primer — for production implementation with eval gates, see RAG in Production.
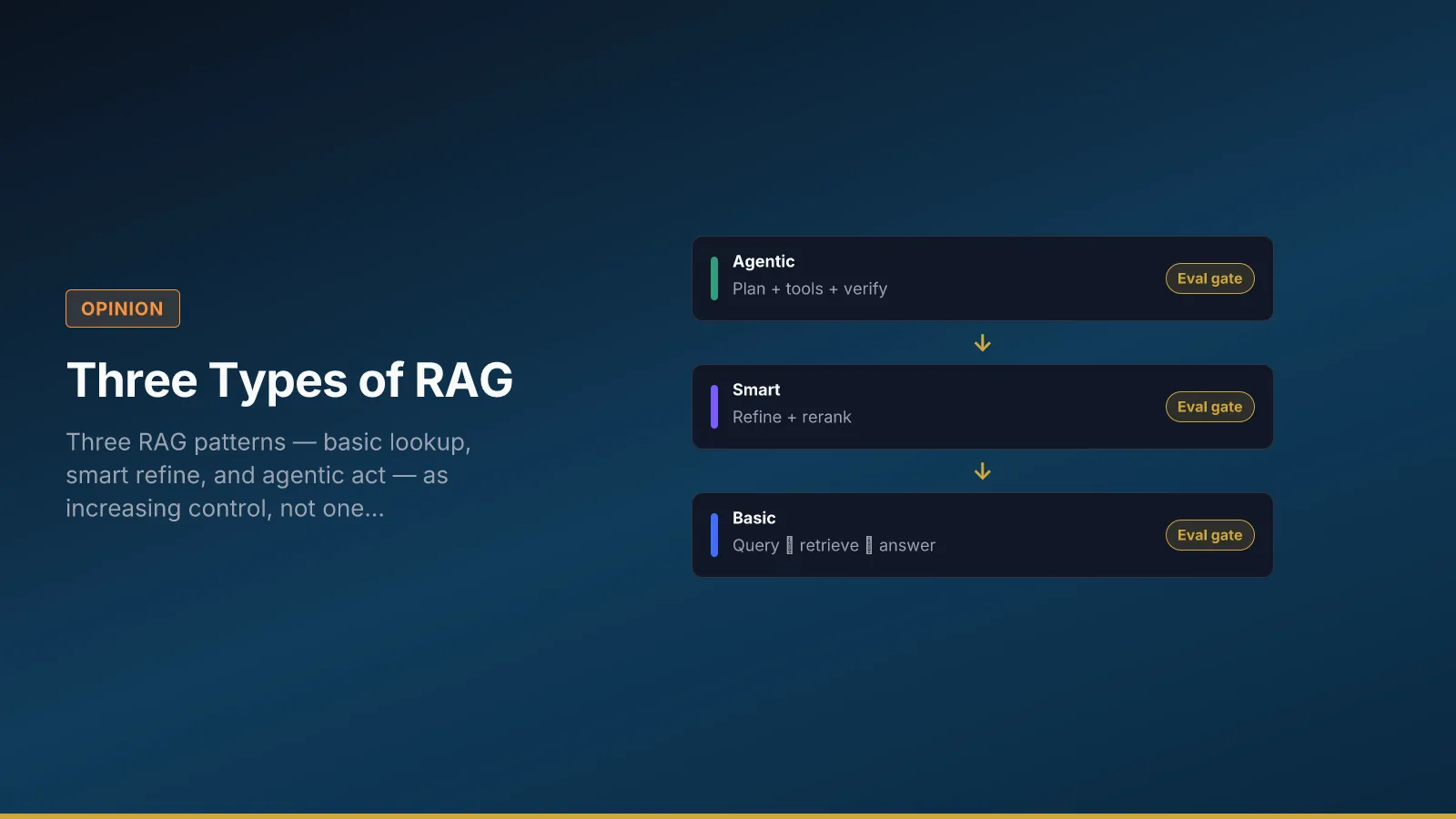
The hero breaks retrieval into three patterns: basic (lookup), smart (refine), agentic (plan, tools, verify). Vendors often sell “RAG” as one switch. Operators need the distinction because each tier adds steps, latency, and failure modes — and because audit questions change when tools enter the loop.
The poster is a risk ladder, not a maturity insult. Many workflows should stay on basic lookup for years. Others need refinement when the corpus is noisy. Agentic patterns are for bounded research tasks with spend caps and human send gates — not for every copilot because the diagram’s third box looks advanced.
Basic RAG — lookup before answer
Flow: query → search approved docs → answer.
Best for: stable knowledge bases, internal FAQs, support macros with citations.
Risk profile: wrong chunk still produces fluent answers — you need held-out eval cases and versioned indexes.
This tier is enough for many workflows if policy packs and denial rules are explicit.
Basic RAG still requires operational hygiene — chunk owners, index version IDs, and denial when confidence is low. Implementation detail lives in RAG in Production.
When Legal asks “which policy version was in context,” basic tier must answer with corpus version IDs — not “the model searched Confluence.”
Smart RAG — refine before generate
Flow: query → retrieve → refine/rerank → answer.
Best for: noisy corpora, long PDFs, mixed-quality wikis.
Why it matters: first-pass retrieval often returns “related but wrong.” Refinement reduces obvious misses without full agent autonomy.
Cost: extra model calls — justify with measured accuracy lift, not intuition.
Smart tier is where teams should prove ROI on a held-out set before promoting tier — see RAG in Production for rerank versioning and eval discipline.
Support leads often feel smart tier is “just better search.” Frame it as quality gates on evidence before generation — same accountability as checkers, different placement in the pipeline.
Agentic RAG — act with verification
Flow: query → plan → tools → verify → answer.
Best for: multi-source investigations, tender research, complex ops tasks — with human gates on send and spend.
Risk profile: tool misuse, runaway loops, unaudited side effects. Requires Data Boundaries for AI Agents and Evaluation Hooks for AI Workflows before production.
Agentic retrieval implies tool allow lists, per-run budgets, and structured traces — not only final text. Full rollout patterns are in RAG in Production and How to Design an AI Agent Workflow.
Choosing a tier (visual labels)
| Label on hero | Risk level | Start when |
|---|---|---|
| Basic — lookup | Lowest step count | Single approved KB, low external risk |
| Smart — refine | Extra model call | Retrieval quality inconsistent |
| Agentic — act | Tools + verification | Multi-step research with human send gate |
Do not deploy agentic RAG because the diagram’s green box looks “most advanced.” Deploy it when accountability matches the step count.
Revisit tier choice when the corpus, regulations, or channel changes. A workflow that was basic can move to smart after repeated wrong-chunk near-misses; it should not jump to agentic because leadership saw a demo. Risk forum should sign tier changes the same way they sign data boundary expansions — with eval evidence and named owners.
Document the active tier in the workflow canvas footer (retrieval_tier: basic|smart|agentic) so incident reviews do not debate what production was supposed to be doing.
Go deeper
Retrieval sits inside context architecture, not instead of it. For the full production guide with tier promotion and eval gates, see RAG in Production. For accountable logging when tiers change, see Audit Trails for AI Workflows. For the broader control ladder that ends at RAG, see Five Levels of AI Control.