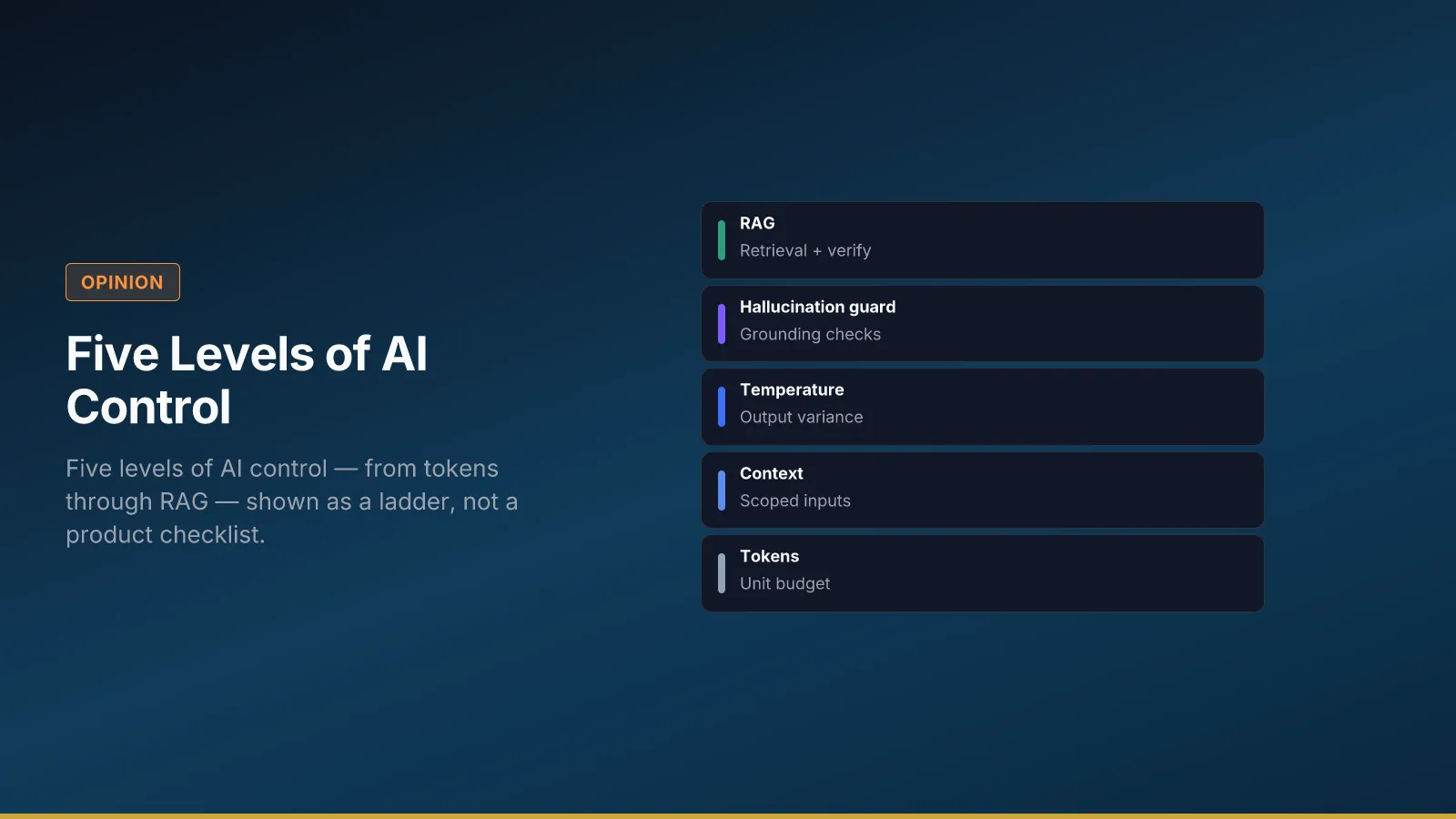
The poster shows a ladder: tokens, context window, temperature, hallucination, RAG. It is not a shopping list for features. It is a reminder that control compounds — and that teams who jump to the top rung without the lower ones confuse access with architecture.
Procurement often arrives with a slide that says “we enabled RAG.” Operations still sees wrong answers because nobody scoped inputs, documented sampling rules, or designed eval before scale. The ladder is a conversation tool for steering and risk forums: which rung you are actually operating on, and what must exist before you claim the next one.
Level 1 — Tokens
Tokens are how models chunk text. They are not understanding. When leaders treat “we have a big token budget” as strategy, operators still see garbled outputs because nobody scoped what may enter the window. Token literacy matters for cost and for knowing why “paste everything” fails — but tokens alone do not govern customer-facing work.
In practice, token awareness shows up in three places: estimating cost per workflow run, explaining truncation when users paste whole tickets, and refusing “just add more context” as a fix. Teams at Level 1 only should not promise accuracy improvements from a larger subscription tier; they should promise a scoped pilot with measured cases. Pair cost conversations with Tokens and Context Window Limits when overflow is the recurring failure mode.
Level 2 — Context window
The window is what the model can see in one run. A larger window does not replace retrieval design, policy layers, or evaluation. If your team believes window size fixes accuracy, read Context Window Myths and then What Is Context Architecture — design what enters the window before you celebrate the limit.
Context discipline means an explicit allow list per workflow: which systems, which document versions, which fields from CRM, and what must never be pasted. Without that spec, a bigger window only increases the surface area for contradictions and stale policy text. Level 2 maturity is visible when Legal can approve a context pack version and ops can replay a run with the same pack hash — not when someone says “we use the 200k model now.”
Level 3 — Temperature
Temperature is a predictability dial, not a personality knob. Low settings stabilize formatting; higher settings explore wording. Production workflows should document allowed ranges per step (draft vs brainstorm) and tie changes to eval regressions — not to whoever preferred “more creative” in a demo.
Treat temperature like any other production parameter: named in the registry, changed through change control, and tested on a held-out set. Marketing may want “more creative” subject lines; support macros need deterministic JSON. Split steps so each has its own range rather than one global slider on a shared copilot. When a near-miss appears after a “small” temperature tweak, that case belongs in the eval set within a week — same rule as prompt text changes.
Level 4 — Hallucination
Hallucination is confidence without ground truth. The ladder places it before RAG on purpose: retrieval does not erase bad workflow. Fluent wrong answers still pass casual review. Pair this level with When AI Hallucinates Confidence and Why AI Hallucinates for the grounded-vs-guessing split.
At Level 4, teams acknowledge that tone and structure are not evidence. They add checker steps, mandatory citations, or human-only fields for numbers and dates before external send. They measure override rates and citation miss rates, not “the answer felt fine.” Skipping this rung while deploying retrieval is how organizations get polished wrong commitments in customer email — the failure mode the poster warns about before you reach RAG.
Level 5 — RAG (retrieval)
RAG grounds answers in approved facts — when retrieval, policy, and eval are designed. It is the top rung because it assumes you already manage tokens, window discipline, sampling settings, and failure modes. Jumping here while chat is still the product is how pilots look brilliant and operations stay fragile.
Not all retrieval is equal. Three Types of RAG distinguishes lookup, refine, and agentic patterns — each adds steps and accountability. Level 5 means indexed corpora with owners, regression eval when indexes change, and audit fields that record which chunks influenced a send. Buying “enterprise RAG” without those artifacts is still Level 1 with a fancier invoice.
Claimed rung vs evidence required
Use this table in steering and risk forums — not to shame teams, but to align slides with artifacts.
| Claimed rung | Evidence required before you claim it |
|---|---|
| Level 1 — Tokens | Cost estimate per workflow; refusal to treat window size as accuracy fix |
| Level 2 — Context window | Versioned context pack + replay with pack hash |
| Level 3 — Temperature | Registry pin + eval on parameter change |
| Level 4 — Hallucination | Checker step or human gate; override/citation metrics |
| Level 5 — RAG | Index owners, tier documented, eval on index change |
Go deeper
The ladder is a visual primer. Implementation lives in Grounding AI Outputs, The Model Is Not the System — workflow, context, evaluation, and governance around the model — and in AI Governance Roles and Ownership when more than one team touches the same workflow. For what comes after basic control, see What Actually Scales AI Beyond Chat Basics before you add agents and tools to an unstable base.