Teams often confuse a single successful tweet with a production loop. Fluency in the copy hides missing schedulers, duplicate fires after a 429, and rows Legal cannot replay after a near-miss. This article documents BTC Buzz Bot—a scheduled X publish loop I built and later paused—not as a crypto opinion piece or trading signal, but as an archived operator field note on what “working fluently” actually required.
After reading The Bitcoin Standard, I wanted a small, steady presence on X around Bitcoin—not price hype, but something readable a few times a day. Coinbase’s pattern helped: short scheduled posts when volatility mattered, inside whatever monthly automation budget your X API tier allows. I started with what I could ship first—a database of inspirational quotes and a cron post. Stage two was live LLM posts from market sentiment. That sounded inspirational on paper. On a Heroku worker dyno, ingest → analyze → compose → post often took longer than the schedule could absorb. The model was not the bottleneck; dyno time, rate limits, and duplicate guards were. For the wider lesson that inference is not the system, see The Model Is Not the System.
The sister repo is DITreneris/btcbuzzbot. Maintenance has been paused since roughly mid-2025; this article teaches the architecture, not a live SLA. The historical account was @BTCBuzzBot.
What BTC Buzz Bot is (and is not)
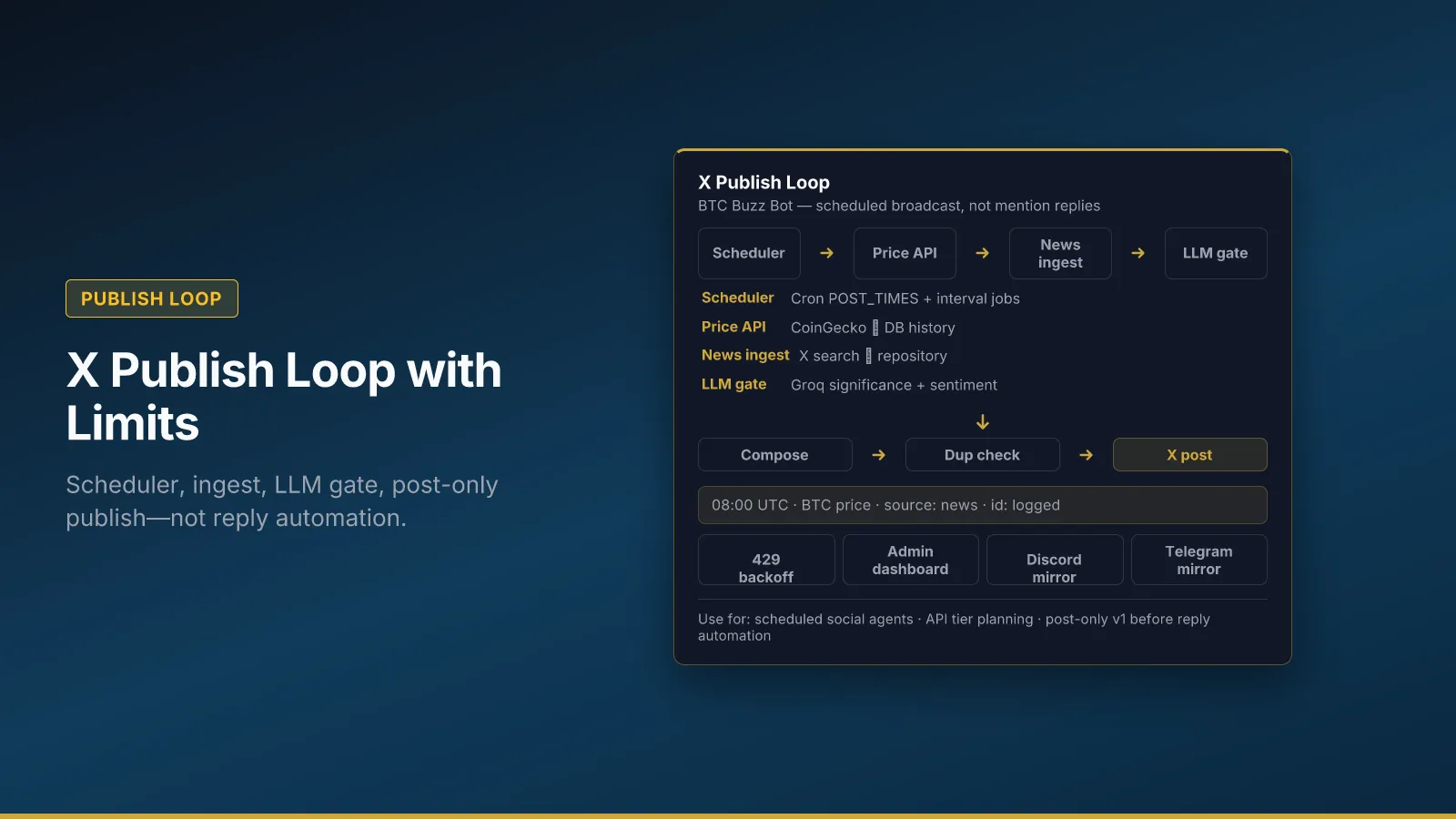
BTC Buzz Bot is post-only X automation: scheduled broadcasts that combine live Bitcoin price context with either LLM-analyzed news summaries or quote/joke fallbacks from a seeded database. Optional Discord and Telegram mirroring and a Flask admin dashboard ran on Heroku (separate web and worker dynos). The bot reads X for news ingest via search; it does not reply to mentions, quote-tweet, or DM.
It is not a Prompt Anatomy property, a training surface, or proof of implementation maturity on .blog. Treat it like Corporate Ladder on .lol—operator lab evidence, not a procurement deck metric. For where sister surfaces fit, see The Prompt Anatomy Ecosystem Map.
Origin — quotes first, LLM sentiment second
The build followed a sensible v1 → v2 path that still went wrong on infrastructure:
- Stage 1 (shipped): Seed a quote and joke database; post on a cron inside X’s monthly post budget for your tier. Bounded, schedulable, easy to replay.
- Stage 2 (ambition): Ingest Bitcoin-related tweets, run Groq analysis for significance and sentiment, and compose posts from live market mood.
- Lesson: Stage 2 on a single Heroku worker made the cadence fragile—analysis intervals overlapped posting slots, cold starts hurt reaction-time expectations, and maintaining fluency cost more operator time than the inspirational output justified.
The repo’s main branch reflects that evolution: ContentManager and quote tables remain the fallback when news analysis is slow, empty, or below significance thresholds. That is the correct pattern—async ingest, batch analyze, gate, then compose—even though I learned it by overloading v1 on one dyno.
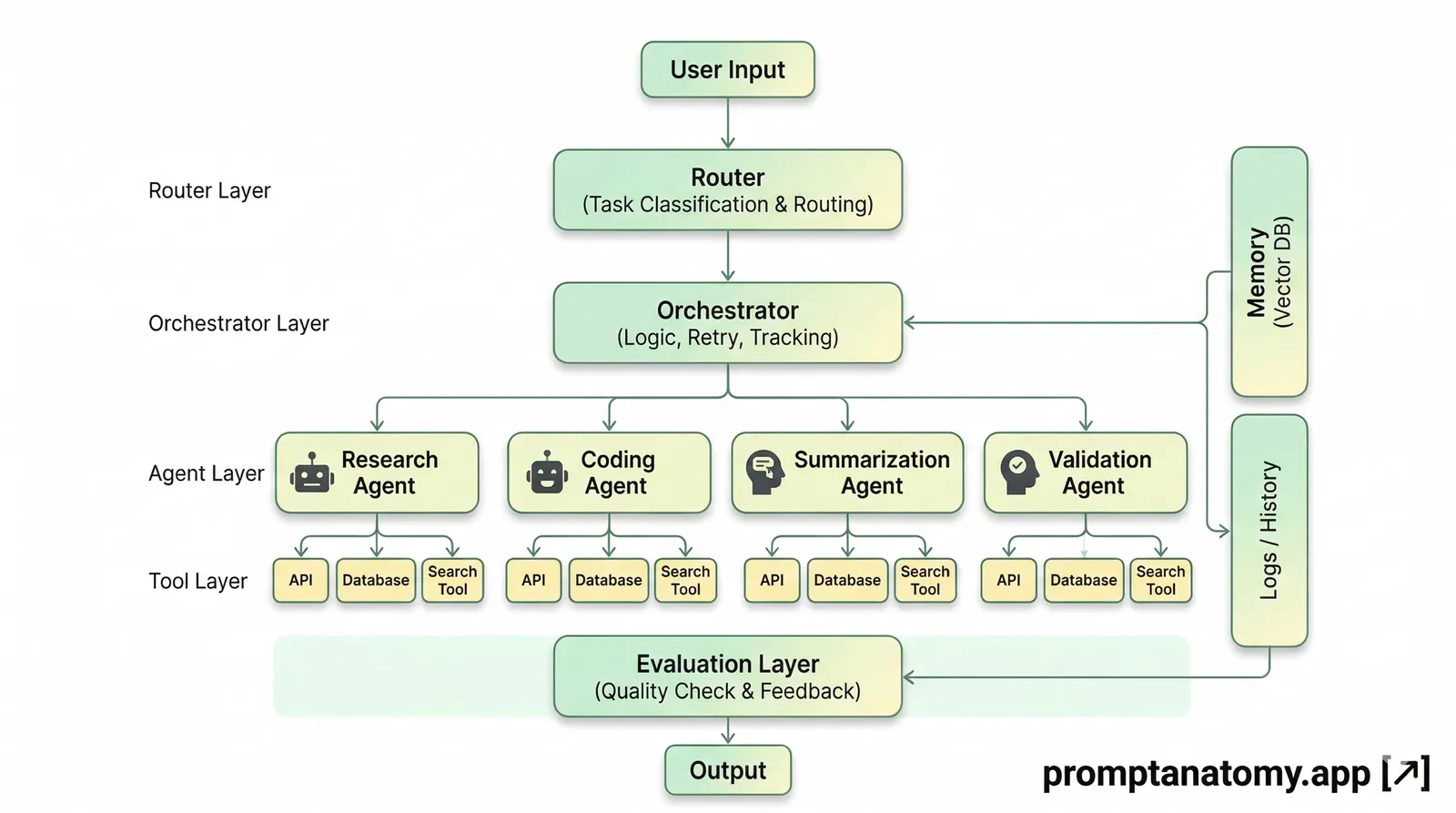
The publish loop (architecture)
Read the pipeline as ownership boundaries, not install order only. Each box is a job something else should not silently duplicate.
| Layer | Job | Failure if skipped |
|---|---|---|
| Worker scheduler | APScheduler cron (POST_TIMES) plus interval jobs for fetch/analyze |
Missed posts with no alert |
| Price fetcher | CoinGecko → price history in DB | Stale or missing price block in every tweet |
| News ingest | X search (#Bitcoin -is:retweet) → repository |
No fresh signal for LLM path |
| LLM analyzer | Groq JSON significance + sentiment; VADER fallback | Random or off-topic broadcast |
| Content gate | High significance ≥0.8; medium ≥0.4 with sentiment rules; stricter when VADER-only | Weak summaries published as news |
| Post composer | Price block + news summary OR quote/joke; 280-char trim | Truncation bugs or tone drift |
| Duplicate guard | Skip if same content window (DUPLICATE_POST_CHECK_MINUTES) |
Double-fire after retries |
| X client | create_tweet via OAuth 1.0a user context |
Auth drift with no logged failure |
| Persistence | SQLite locally; PostgreSQL on Heroku | No replay after an incident |
| Admin web | Flask dashboard and /api/* health |
Blind operations |
The operator path in one line:
cron post → fetch price → pick analyzed news OR quote/joke → duplicate check → create_tweet → log row → optional Discord/Telegram
Separate ingest, analyze, compose, and publish—the same discipline as How to Design an AI Agent Workflow—even when the surface is a single-account social bot.
What “working fluently” actually meant
Fluent did not mean the LLM returned clever copy. It meant the loop could run without you watching:
- Scheduler reliability — cron loaded from DB
scheduler_config; worker dyno separate from the Flask web process. - API backoff —
RateLimitErrorandTooManyRequestscaught; engagement refresh sleeps between metric fetches; fetch cycles skip instead of hammering X. - Duplicate guard — default five-minute window prevents the same slot from firing twice after a partial failure.
- Content reuse window —
CONTENT_REUSE_DAYSstops quote/joke rotation from becoming spam. - Structured LLM output — JSON significance before the tweet body trusts the summary.
- Observability — posts table, bot logs, and health scripts so you can answer “what went out at 08:00 UTC?” without opening X.
Persisted rows beat chat fluency—see Audit Trails for AI Workflows. If you cannot replay a post with source and timestamp, you do not have governance—you have hope.
Guardrails table
Outbound social automation needs the same draft-and-boundary thinking as email—compare AI Outreach with Outlook Guardrails.
| Control | Config / behavior | Purpose |
|---|---|---|
| Post-only v1 | No reply or mention handlers | Avoid ungoverned engagement |
| Significance gate | High ≥0.8; medium ≥0.4 + sentiment rules | Block weak LLM summaries |
| Duplicate check | Five-minute default window | Prevent double-fire |
| Max length | 280 characters | Platform compliance |
| Financial disclaimer | README tone; informational only | Not investment advice |
| Web rate limits | Flask-Limiter on admin routes | Protect dashboard from abuse |
| Feature flags | ENABLE_DISCORD_POSTING, ENABLE_TELEGRAM_POSTING |
Isolate blast radius |
| Quote DB fallback | ContentManager when pipeline is slow or empty |
Keep cadence without fake news |
Treat API keys and bearer tokens as data boundaries—env vars only, never in the repo, rotate when staff changes.
Honest limits and maintenance status
Maintenance is paused since roughly 2025-06. The Heroku app may be cold; X API tiers and Groq model IDs may differ from the build described here. The experimental scheduler_llm.py Ollama path is not the production Heroku path—do not copy it blindly.
This is not a template for regulated industries’ social programs without Legal review. BTC engagement is not AI implementation maturity—if your steering deck cites bot impressions instead of pass rate and incident cost, redirect to Measuring AI Workflow ROI. When you choose where this pattern lives, compare hosting and operating models in Choosing Workflow Automation for AI Pipelines—dyno pairs, schedulers, and observability matter more than demo flash.
If you want the code, start with the sister repo and .env.example—ship quote DB plus cron first; add LLM sentiment only when analyze-and-post fits your worker budget and you can gate output before publish.