Anonymized composite (Northline B2B)—multiple implementations.
Situation
A 120-person B2B services company had copilots in support, sales, and marketing within a year. Leadership dashboards showed rising “AI activity”—messages generated, licenses assigned, teams onboarded. CSAT on assisted queues flatlined. Support leads spent evenings rewriting drafts that sounded authoritative but cited wrong policy or wrong product facts. Reps in the same tier produced incompatible answers on identical ticket types because each had personal prompt habits and sidebar tools IT never approved.
The team scored 8 of 10 on the vibe prompting diagnostic—strong activity, weak system. Executive sponsor asked which model to upgrade; process owners asked for time to fix one queue. This case follows the queue that won: tier-2 support assist, workflow ID support-reply-v3.
Approach
Leadership agreed to pause new tool trials for ninety days—politically difficult, but necessary to stop variance growth. The program selected one workflow with a named owner, filled the workflow canvas, and treated everything else as experiment backlog.
Context came from forty KB articles tagged customer-safe and policy pack support-policy-2026-04 owned by Legal—not paste-in from agents’ personal notes. Checker step flagged unsupported claims before an agent edited. Human send remained mandatory in v1; no auto-reply to customers. Logging followed audit trail spec including policy_pack_version after a near-miss on deprecated refund language.
Governance RACI from roles guide named Support ops accountable for eval pass rate. Monthly risk forum voted shadow traffic increases only when pass rate held—fifty to eighty percent queue coverage over twelve weeks, not day-one full automation.
Eval set and context versioning
Quality was defined before prompt tuning debates. Twenty-five held-out tickets with known-good outcomes; fail on policy violation, wrong product fact, or missing VIP escalation. Smoke gate: ten cases, one hundred percent pass before pilot traffic. Pilot gate: weekly pass rate at or above ninety-two percent with override review.
Context pack changes required Legal bump, KB re-tagging, and eval re-run—version logged on every production row. Architecture choices are documented in context architecture; registry pins in structured prompt system.
Starting eval earlier would have saved roughly two weeks rework in week six when a model swap looked attractive but failed three policy cases.
Results (ranges)
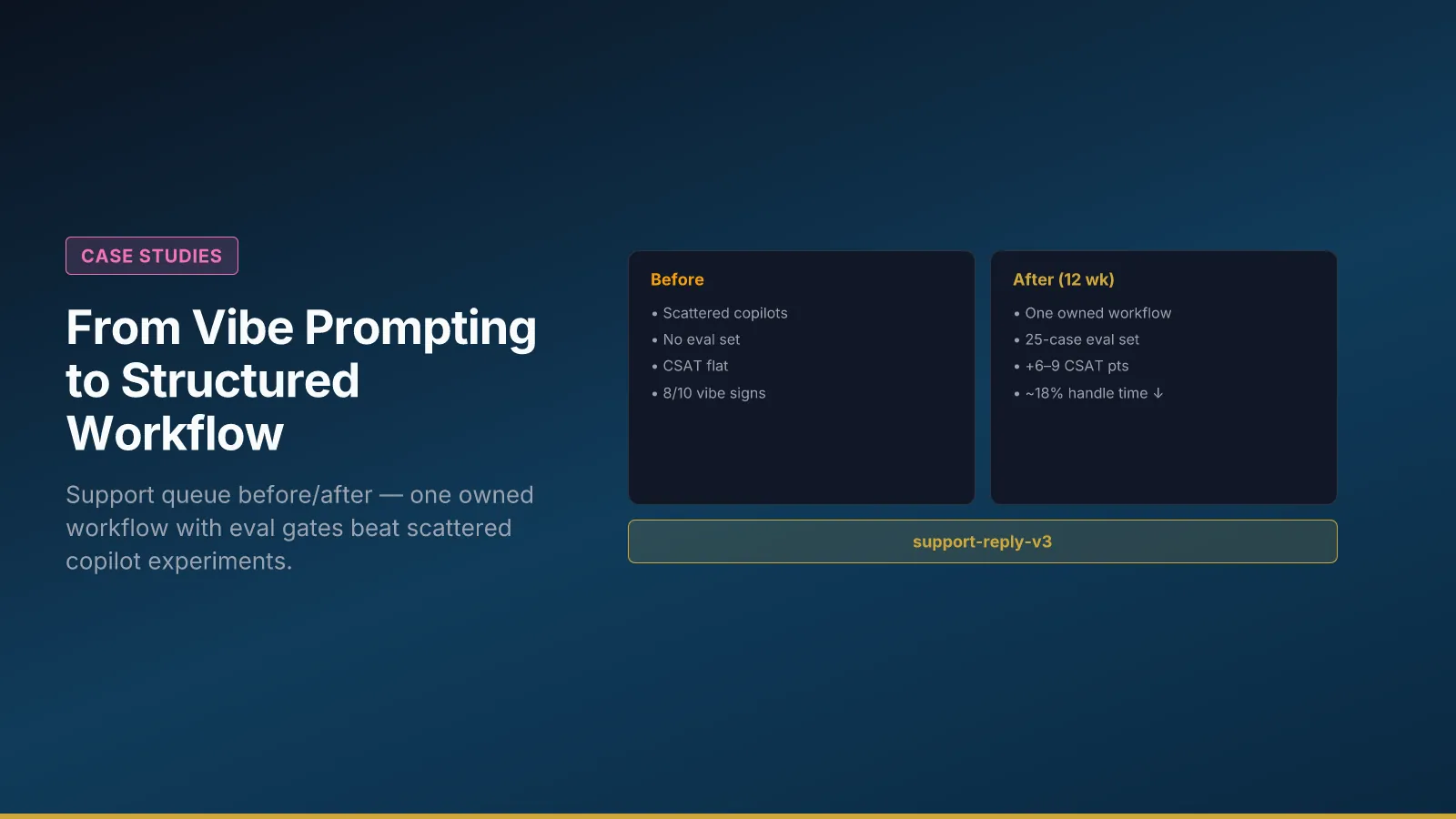
Outcomes were measured on median handle time and CSAT on the assisted queue—not drafts generated. Baseline window: eight weeks pre-pilot. Pilot window: twelve weeks at bounded traffic.
| Metric | Before (8 wk avg) | After (12 wk pilot) |
|---|---|---|
| Median handle time | baseline | ~18% lower |
| CSAT on assisted queue | flat | +6–9 pts |
| Escalations from wrong policy | frequent | down sharply |
| Reproducibility across agents | low | high on eval set |
Activity metrics were reported for transparency but not used for promotion decisions—preventing “more AI text” as success.
Lessons
Diagnostics focused the organization on one process instead of tool religion. Model vendor changes mattered less than context discipline and eval gates—aligned with the model is not the system. Leadership protecting ninety-day scope mattered as much as technical choices; side pilots would have reintroduced vibe prompting through the back door.
Publishing a change log when policy packs updated reduced agent distrust—they saw version numbers in UI, not mystery drift.
What they would do differently
Start eval cases before prompt workshops—workshops produced elegant phrasing that failed case #7. Involve support leads in KB tagging week one, not week six after Legal near-miss. Assign deputy process owner before vacation week in pilot. Link forum minutes to registry version in changelog—audit replay became easier in month four.
Next step for readers
If your team mirrors this story—high activity, low reproducibility—run the diagnostic, pick one queue, fill the canvas, and schedule biweekly eval review before the next vendor demo. Depth on outcomes mapping: from prompts to business outcomes. Depth on maturity placement: implementation ladder.
Part 2: Scaling eval coverage from 50% to 80% queue traffic — how Northline expanded shadow traffic after pass rate held.