Multi-agent workflows fail in ways single-prompt systems never do. One agent rewrites assumptions. Another executes stale instructions. The final output looks polished while being operationally wrong. If you cannot see who handed what to whom, and under which policy or version context, you cannot debug or govern the system.
This playbook gives you a practical observability baseline for production multi-agent systems. Pair it with Multi-Agent Handoff Pattern for orchestration design, and Audit Trails for AI Workflows for governance evidence requirements.
What observability must answer
For every run, your logs should answer five questions in under five minutes:
- Which agent made each decision?
- What context, tool output, and policy version was visible at that step?
- Why did a handoff happen?
- Which guardrails fired, and which were bypassed with human approval?
- Where did quality or latency degrade relative to the last stable release?
If your stack cannot answer these, you are not operating a multi-agent workflow; you are running distributed guesswork.
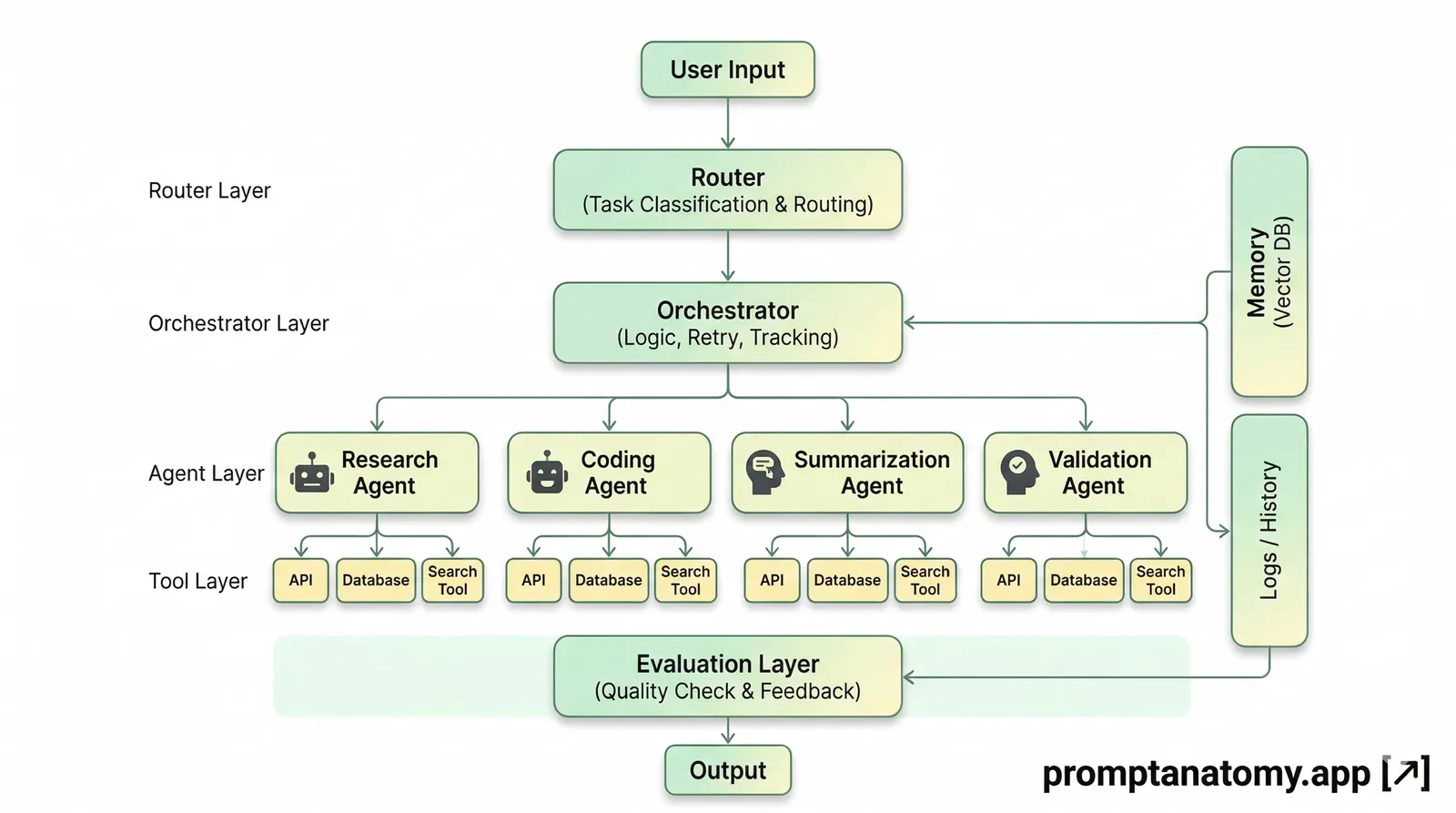
Minimum event schema
Start with a shared event envelope across all agents and tools.
| Field | Why it matters |
|---|---|
run_id |
Correlates every event in one workflow run |
step_id |
Identifies each handoff step uniquely |
agent_id |
Distinguishes orchestrator vs specialist roles |
handoff_reason |
Captures why control moved to another agent |
prompt_version |
Reconstructs behavior after prompt changes |
context_bundle_version |
Replays retrieval/context state |
policy_pack_version |
Proves compliance state at run time |
tool_calls |
Shows dependencies and side effects |
decision_outcome |
Records accept/reject/escalate actions |
human_gate |
Indicates required or optional human review |
latency_ms |
Supports SLA and bottleneck analysis |
eval_case_id |
Links run behavior to eval coverage |
This schema aligns with governance ownership in AI Governance Roles and Ownership: process owners need outcome visibility, IT needs integration evidence, and legal/compliance needs policy replayability.
Handoff trace design
A handoff is not “agent B got a message.” It is a contract with traceable intent.
Log each handoff as a structured object:
- Source and target agent IDs
- Task contract (what must be produced, in what format)
- Input artifact hashes (not raw secrets or full PII payloads)
- Deadline/SLA
- Guardrail state (which checks already passed)
- Escalation threshold (when target must return control)
When teams skip this, they get “handoff drift”: the downstream agent interprets a broader task than intended and returns plausible but off-scope output.
Common failure modes and detection signals
1) Silent scope creep
Symptom: Agent outputs include actions not requested by the upstream contract.
Signal: Growing mismatch between declared task type and executed tool call categories.
Fix: Add contract conformance check before downstream tool execution.
2) Context skew between agents
Symptom: Agent A references policy v3; Agent B cites v2 and produces conflicting advice.
Signal: Mixed context_bundle_version or policy_pack_version values in one run_id.
Fix: Enforce run-scoped context pinning; fail closed on version mismatch.
3) Handoff ping-pong loops
Symptom: Agents repeatedly hand off without terminating conditions.
Signal: Repeated source->target->source cycles with no state transition.
Fix: Set max handoff depth and mandatory human escalation trigger.
4) Guardrail shadowing
Symptom: A downstream agent bypasses a safety check because the check only exists in one agent’s prompt.
Signal: Write tool call appears without expected guardrail event.
Fix: Move critical checks to workflow-level middleware, not persona text.
5) Latency cliff after model or tool update
Symptom: SLA suddenly breached despite similar workload.
Signal: Step-level p95 latency spike concentrated in one agent/tool edge.
Fix: Release rollback or route high-latency paths through a cheaper fallback chain.
Operational dashboard (v1)
Track a small, decision-focused set of metrics:
| Metric | Target use |
|---|---|
| Handoff success rate | Reliability of inter-agent contracts |
| Escalation rate | Human workload and risk concentration |
| Rework rate after handoff | Quality of task decomposition |
| Policy violation intercepts | Guardrail efficacy |
| Median and p95 step latency | Bottleneck diagnosis |
| Cost per successful run | Economic viability |
Use this dashboard alongside AI Workflow Eval Checklist to avoid the anti-pattern of “monitoring only production incidents.”
Northline pattern: support triage + responder chain
Northline B2B used a two-agent chain for tier-2 support:
- Triage agent classifies issue and sets risk flags.
- Responder agent drafts bounded responses with citations.
- Human gate required when VIP, legal keyword, or low confidence appears.
Their first incident was not model hallucination. It was an observability gap: triage handed off “billing issue” while responder received “refund approved.” Logs lacked a structured handoff contract, so reconstruction took hours. After adding handoff reasons and artifact hashes, similar incidents were triaged in minutes and fed into eval updates.
See outcome framing in From Prompts to Business Outcomes and Northline evidence style in Northline Part 2: Scaling Eval Coverage.
Monday implementation checklist
- Standardize one shared event envelope across all agents.
- Add explicit handoff contract logging to every inter-agent step.
- Pin context/policy versions per run and fail on mismatch.
- Set max handoff depth with mandatory escalation.
- Review one recent incident and map which missing log fields blocked root cause.
Multi-agent systems need the same discipline as distributed software systems: traceable contracts, bounded components, and observable failure. If your team can replay a failed run end-to-end with evidence, you can improve safely. If not, postpone added autonomy until observability catches up. Vertical example with send guardrails: AI Outreach with Outlook Guardrails.